

前言
一个迟到的年终总结。
今年其实有很多时候突然迸发出灵感,对某个技术感兴趣或者想要分享点什么,但是打开编辑器创建文件之后就懒了,可能是进入了一种很奇妙的状态,我可以开着编辑器然后 afk 去干任何事,比如连着刷上几个小时的手机,就是提不起来一点动力去写点文字,这不太行,2026 年得尽量多写一点技术积累了。
相比于以往,今年(去年?)多了一些东西,大概是防止自己变得无趣。
- 做一把键盘
- 做一首音乐
- 画一幅画
- 完成一次数字媒体艺术
- 谈一场恋爱
- 去一次世界的尽头
- 推动一次人类进步
但是一年过去了,一项也没有完成。
科研与毕设
反汇编算法
我的毕业设计课题是“基于概率迭代的反汇编算法优化”,这个工作基于 2019 年的概率迭代反汇编算法 [1];在现有的研究中,最为常见的反汇编技术分为两种 [2],一种是线性扫描算法,通过某个指令起始地址向下按顺序扫描来得到反汇编的结果。由于线性扫描算法不通过数据流和控制流进行分析判断,因此拥有很高的覆盖率;它无法处理数据与代码混杂的情况,遇到代码中夹杂的数据时,线性扫描算法会产生大量的误报指令。
另一种递归下降算法可以很好的解决这个问题,递归下降算法通过分析控制流中的静态跳转指令来决定下一条指令的位置,因此相比于线性扫描算法而言,递归下降算法拥有很低的误报率;但是如果源程序采用了类似 jmp rax 的动态跳转机制,递归下降算法无法跟随动态跳转指令决定目标指令的地址,这导致递归下降算法的覆盖率非常低。
先进的反汇编器例如 IDA、Radare2、Rizin、BAP 等等,通常将线性扫描算法和递归下降算法结合起来,辅以启发式规则来指导反汇编器选择正确的算法和策略,从而同时达到较高的准确率与较低的误报率。此类启发式规则通常依赖工程经验与编译器特性,例如通过 push rbp 等开栈操作识别函数起始点、通过寄存器“定义 - 使用”规则来识别误报指令等等。此类启发式规则通常没有正确性保证,在遇到某些采用对抗策略混淆的二进制程序时,这些规则反而会增加误报率。
最近有另一类叫作“超集反汇编” [3] 的技术开始崭露头角,超集反汇编算法不对程序的入口点做任何假设,将所有单字节地址都视为指令的起始地址并进行反汇编操作。超集反汇编产生的结果一定是所有正确指令的超集,但是这个超集中所包含的无效指令可能高达 80% 以上。Miller 等人 [1] 的工作在超集反汇编的基础上引入了概率分析,首先使用特征匹配为一些指令附加先验概率,随后使用基本块内传播、控制流传播、数据流传播等方法计算其他指令的概率,最终整理出合法指令。我的毕业设计就从这里开始。
在构思这个毕设的实现时,我发现原论文中有两个优化的方向。
一个是在性能上,因为论文本身是一个概念原型,所以设计时并没有考虑到大型二进制文件的反汇编优化问题,概率传播需要跟随控制流四处跳转,大概要把指令循环往复好几遍;而超集反汇编本身就会比真实反汇编指令多出 80% 的扫描量,导致这个算法的性能十分的差。于是,我们可以从性能上入手,利用多线程去优化反汇编的流程,并尝试寻找解决并发冲突的方案,实现一个比较高效的带锁并发或者无锁并发。这个方向的问题主要在于创新能力不够,并没有什么理论上的进展,反而是工程量巨大,对架构设计也是一种考验。如果照着这个方向走下去的话,大概是发不了什么会议期刊的。
另一个方向就比较的科研了,也是我上半年主要在做的方向。这个方向主要是研究某个指令为正确指令的先验概率附加算法。在基座论文中,作者靠人力总结了很多个基于工程经验的先验概率附加算法,例如 rdx 在汇编指令中先定义,后使用,以及前后的指令模式基本是一致的,所以可以寻找到对应的数据模式,给这一段指令附加先验概率等等。这种方式的准确性几乎完全依赖于工程经验以及这个没有任何科学依据的先验概率,如果有二进制文件针对这一套工程经验法则进行特殊的混淆攻击,那用这个算法跑出来的结果基本上就废掉了。所以另一个方向就是设计一套更加科学的特征匹配与概率附加规则,而这条路很难走。
其他工作:动态插桩
在 2024 年到 2025 年上半年的时候,我跟着一个应该算比较知名的二进制 fuzzing 组一起做了一些关于二进制插桩和静态识别的工作,大概是有一个商业项目,一个科研上的工作。由于一些对方的原因,商业项目不了了之,而科研工作一直在继续推进,最后我这边产出了一个可以在运行时动态开关 ASAN [4] 的工具以及相关的研究,而对方在产出什么我至今都不知全貌,只听过他讲了一些原理,也没有看见过相关的代码。最终这个合作不欢而散,对方承诺不会使用我产出的部分,我这几天应该会在这里更新一篇博客来讲一下这个研究具体做了什么。在合作破裂之后,我曾经想着把这一部分拿出来单独产出一篇论文,但是它的应用很不完整,科研含金量也并不多,在一些场景下还存在错误 patch 的风险,所以还是当成技术博客发表比较好。
实习与秋招
2025 年 3 月初的时候忽然意识到马上该找工作了。
由于科研上实在是做不下去,于是花了两秒钟就打消了继续读博士的念头。但是以后究竟要做什么呢?以我的技术栈而言,可能啥都会一点,也啥都不太精通,这在找工作时其实是一个很大的缺陷。我在春招实习投递的时候大约投了有四五家游戏公司,没有一家过简历给面试机会的,甚至没有给笔试机会的。最后思来想去,我的简历和项目经历可能还是投开发相关的岗位会好一点;又因为不是很想变成 CRUD 工具人,最后投递了字节跳动基础架构相关的岗位。很幸运的是一次性通过,并且遇到了一群很好的同事,一起做了一些有意思的事情。
在上海生活了四个月。最初投递 base 地的时候选上海,主要是想着国内二次元圣地,这下没去过的漫展一定要去一下,没参加过的线下活动也一定要参加一下,我要化身二次元现充!
结果 Bilibili World 没抢到票;China Joy 抢到票了,但在开展前一天下午急性阑尾炎,在长海医院做了手术躺了三天,票还忘退了;BeatVerse 的主办方与承办公司三*喵沟通不畅,给所有人退票然后无限期推迟了;
……果然是越期待什么就越难得到什么。
实习转正大概也算顺利,紧接着就是秋招。秋招的时候,我大概把所有的互联网公司以及一些不太互联网的公司全部面试了一遍,遇到的情况无非就是以下几种:
- 安全岗面试官:你这么多开源贡献,为什么不去面开发?
- 开发岗面试官:你打了这么多年 CTF,学了七年网络安全,为什么不去面安全?
- 面试官:讲一讲 Ret2Shell 这个项目,我讲到口干舌燥,最后跟他说这个就是 ctf.xidian.edu.cn,每年能承载四千多人比赛,MoeCTF 是目前全国规模最大的新生赛之一。
- 面试官信了,去翻了翻我的 GitHub,接下来一路绿灯就过去了;
- 面试官不信,觉得这么大的项目你一个人写不完,不过你这么有自信,那就来写个算法吧,发了一道红题,人傻了;
- 面试官觉得这就是个课程设计大作业级别的玩具,敷衍两句给挂了;
- 面试官只是为了完成 KPI,听我讲完就下线给我挂了;
最后还是拿了一些不错的 offer,最终选择了转正留在字节,继续做基架相关的工作。
与 2023 年本科毕业时不同,今年找工作明显的感觉到难度飙升。另外也感受到了大厂更关注在某一方面深耕并且有所成就的人,什么都会一点也同样意味着什么都干不好,一个人的精力是有限的,在不缺人力的情况下,公司完全可以把一份完整的工作交给四五个在各自方向十分精通的人去做好,而不是交给一个什么都会的人(即使他什么都精通)去做,在时间压力之下即使精通也可能什么方面都做不好。
一些好玩的东西
2025 年大概可以算是一个人生节点,决定了至少未来五到十年的走向。这些事情在上面已经讲的差不多了,一些细节内容后面可能会单开博客来说。
对我来说,生活大概就是做一件完整的、有乐趣的作品出来,并以此往复。这种大约理想主义的做法支撑着我过完了近五年的生活,所以今年究竟都做了什么还是有必要回顾一下的。
继续办了几场比赛
除开每年的固定任务 Mini-L CTF 和 MoeCTF 之外,2025 年承办了:
- DCTF 2025,由于 Vidar 队内的一些原因,今年的 DCTF 失去了老赞助商,于是换成了我的平台,但运维仍旧是 Vidar 那边来做。比赛期间也出现了一些运维问题,不过并没有需要(允许)我介入,所以大概也无法总结平台的问题。不过总的来说,比赛还是顺利办完的。
- VNCTF 2025,比赛中途由于运维之间的私人矛盾导致了一些删库(有备份,后来恢复了)、夺权等等一系列的事件,并在比赛开始之后网站在亚健康状态持续了 48 分钟(容器配额出现问题,FRP 转发的域也不够大)。由于这次承办在最初商量的是我提供软件,V&N 自己人来运维,后面闹了矛盾之后我全部接手了运维工作,但时间紧迫并没有摸清楚网站的部署架构,在赛中修复花了很大力气。这场比赛是 回归终端 走出 西电 的第一站,也是崩得最厉害的一站,给我的教训大概就是,在对合作人知根知底之前,不要轻易把运维工作交付出去。
- NepCTF 2025,很顺畅的一次办赛体验,NepNep 的师傅们给了非常完善的支持和适配。虽然比赛中途出现了一些小插曲,服务器断电了导致比赛中断约半小时,但毕竟是天灾,不可避免的意外并不是需要反思的理由。
- R3CTF 2025,和好兄弟 Hydrogen0E7 以及著名的 crazyman_army 一起办了 r3kapig 的国际赛 R3CTF,有了前两次外部办赛的经验,这次承办在比赛全程没有发生任何可用性问题。
- WannaGame 2025,完全在海外的第一场比赛,给越南胡志明市国立大学的网友举办了一次比赛,由于对方时区不太一样,告知错了比赛时间,导致比赛开始的第一个小时完全无人值守。不过好在平台软件本身足够稳定,整场比赛也没有出现任何问题。
我打算在 2026 年晚些时候将平台开源在 GitHub/ret2shell 上,以后虽然工作了时间不多,但毕竟自己亲生的,也不是很想看它沉寂在历史尘埃之中。
自己造一把键盘
实习结束回来,我在 2025 年初斥巨资买的 IQUNIX MG65 也因为旅途劳顿,一些键出现了双击/三击,另一些键则完全不触发。其实是花十几块钱换几个轴就能大概解决的问题,但是这么容易坏的东西实在很让人不爽。再加上我一直想要在键盘上加一些自己的功能,最后索性自己从工业建模开始,先后学了数电设计等等学科,最后在好朋友们 HankZ、syml 的帮助下,大概是完成了概念设计,在 GitHub/Reverier-Xu/keysdock 存档,等待后续的制造验证。
在设计键盘的时候,我突然有一些奇想,不知道全开源的方案能不能完成这项工作。于是选择了 FreeCAD 做工业建模,Blender 做物料渲染,KiCAD 做电路设计,以及 QUCS-s 做电路仿真验证。MCU 选择了基于开源指令集架构 RISC-V 的 ESP32-C6,辅以 TI 的电源管理与 ADC 芯片做采集,最终设计了一套磁轴键盘方案出来。今年应该会继续完善这套方案并安排小批量生产,还有即将要写的网页驱动在 keys.woooo.tech。

新的设计系统
今年年中的时候苹果发布了新的 Fluid Glass,说实话,第一眼看到的时候感觉是苹果的设计师喝高了搞出来的,透明度会影响可读性的问题哪怕是在野路子学平面设计的时候都是最先学到的那部分,但 iOS 26 的前几个版本在发布之后可读性还是一大坨。不过除开可读性之外,用浮动元素来模糊内容边界,让整体视觉更加通畅的设计思路确实很惊艳。移动设备上可能感觉并没有那么的明显,在我实习结束前,我给公司电脑升级到了 macOS 26,在文件管理器上体验马上就上去了,在采用新设计之前,原先的 Finder 大概可以评价为包含 Windows 和所有 Linux 发行版上的文件管理软件在内最烂的一个,采用新设计之后……好像也是最烂的那个,不过使用体验比以前好多了。
于是年底的时候,我就在想要不要改一改自己的设计风格,我之前的设计风格基本已经固定下来了,从 回归终端 到重构之前的博客基本上都是继承自 Daisy UI 修正而来的,减弱了动画效果,引入了模糊与噪点,并从依据文字大小来决定视觉重点的方案转换成了依靠透明度的方案。如今要在维持自己设计风格的基础上向苹果新设计风格的布局思路靠近,似乎并不是一件很容易做到的事情。
不过当大伙看到这篇博客的时候,大概也注意到博客网站的整体变更了,其实我还挺满意的。这个设计系统在布局简单的内容驱动网站上十分的优秀,但是在功能驱动的网站上难度就很大。
就以博客为例子,在设计评论区的时候就遇到了很大的困难。为了彻底适配博客的设计风格又不丢失旧的评论,研究了很久如何 hack 掉 giscus 的组件样式表,最后在代码里发现 giscus 本身的组件是和 giscus app server 耦合的,而真正集成到博客网页上的是一个 iframe 框,然后再通过 iframe 传递的样式属性对内应用样式。于是最后我在 DeepWiki 上找了一份 giscus server 的 api 列表,从 api 封装了一层,然后自己写评论组件了,此时真正的设计难题才刚刚开始。
具体来说,这个设计系统的整体思路是将内容空间在视觉占比上扩张到 100%,然后在不影响内容的位置放上一些小的操控组件,并给操控组件分组附加背景容器,来使其看起来像是“浮动”在页面上的。在内容居多,控件偏少的情况下,效果很出色;但是当控件多起来之后,视觉效果就从简洁开阔变成了冗杂混乱。评论区就是这样一个情况,每个评论都有用户头像、用户名、时间等等元素,如果按照控件的规格加上背景容器,那么就是一大排黑圆圈排着,看起来十分难受;GitHub Discussions 还支持了评论的回复功能,我们还要在每个顶层评论下面添加有关回复的输入框,并在整个评论区底部添加一个发表新评论的输入框。
输入框又是支持 Markdown 语法的,只放一行很显然不合适,于是按照传统设计思路来排布,看起来就会变成这样:
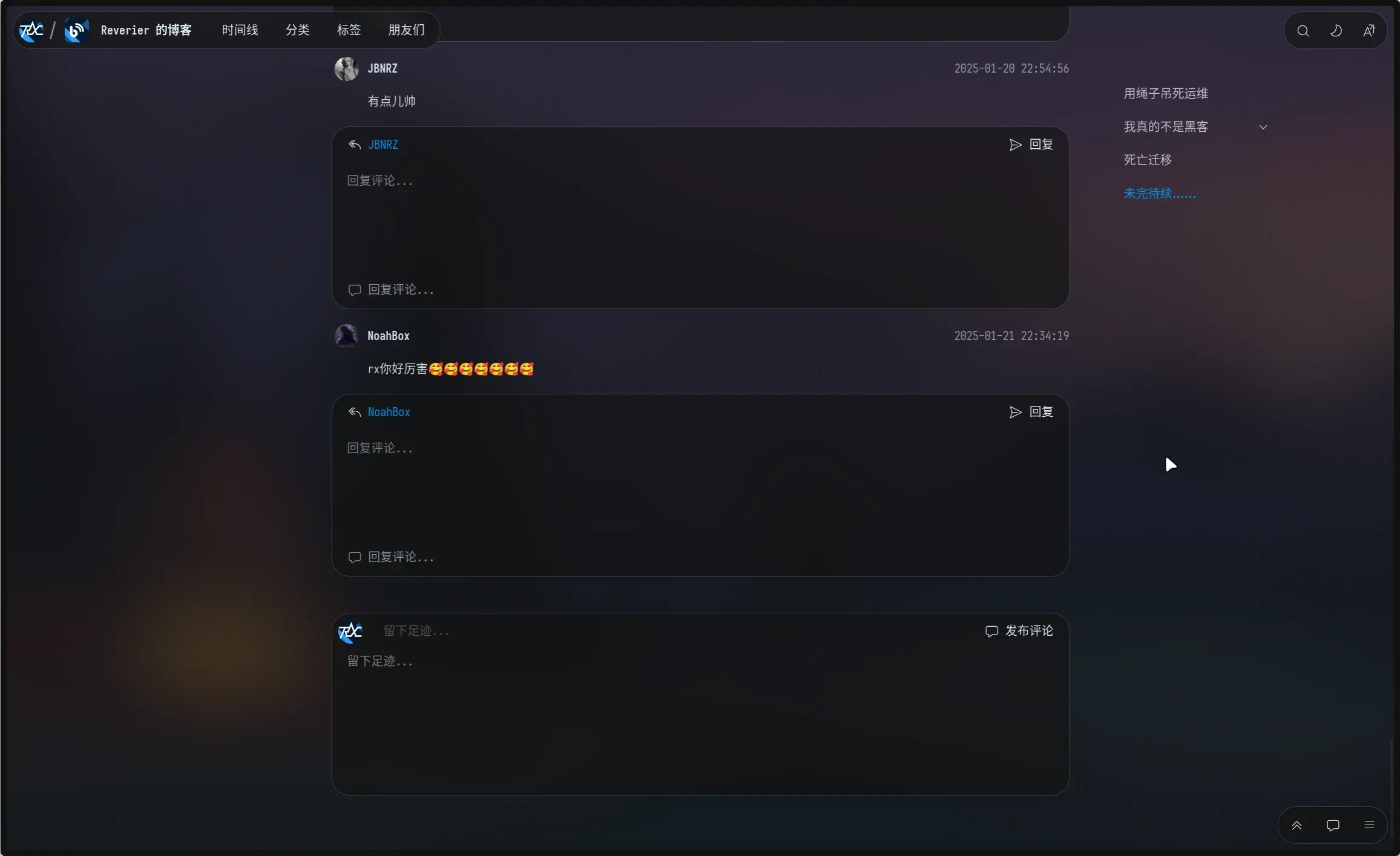
这个效果只能说很难评,和浮动组件相同的视觉层级,但是占据了大部分页面空间。如果给回复统一改到评论的框里可能会改善一下视觉体验,但是如果访客要回复一个很靠上的帖子,结果点了一下回复按钮,自动聚焦到最下面的输入框去了,那就更难评了。
于是我开始寻找有没有什么能 抄 借鉴的的设计方案,大概是找到了两种,一种是通过弹出层,将回复框放入对话框里,然后在对话框弹出的时候模糊下层内容;另一种是先放一个透明的按钮,点击的时候再展开输入框。
前一种方案在设计搜索层的时候非常好使,但是设计评论区不然。访客在回复评论的时候很显然是希望看到原文的,弹出框给原文挡住了不说,背景还模糊了一下,更看不到了;另一个问题是如果弹出框关闭了,到底要不要清空用户的输入内容,这问题蛮多的。
于是最后采用了后一种方案,由于整套组件全部自己重制了,有了很大的定制花里胡哨功能的余地,例如评论 Markdown 的实时预览:
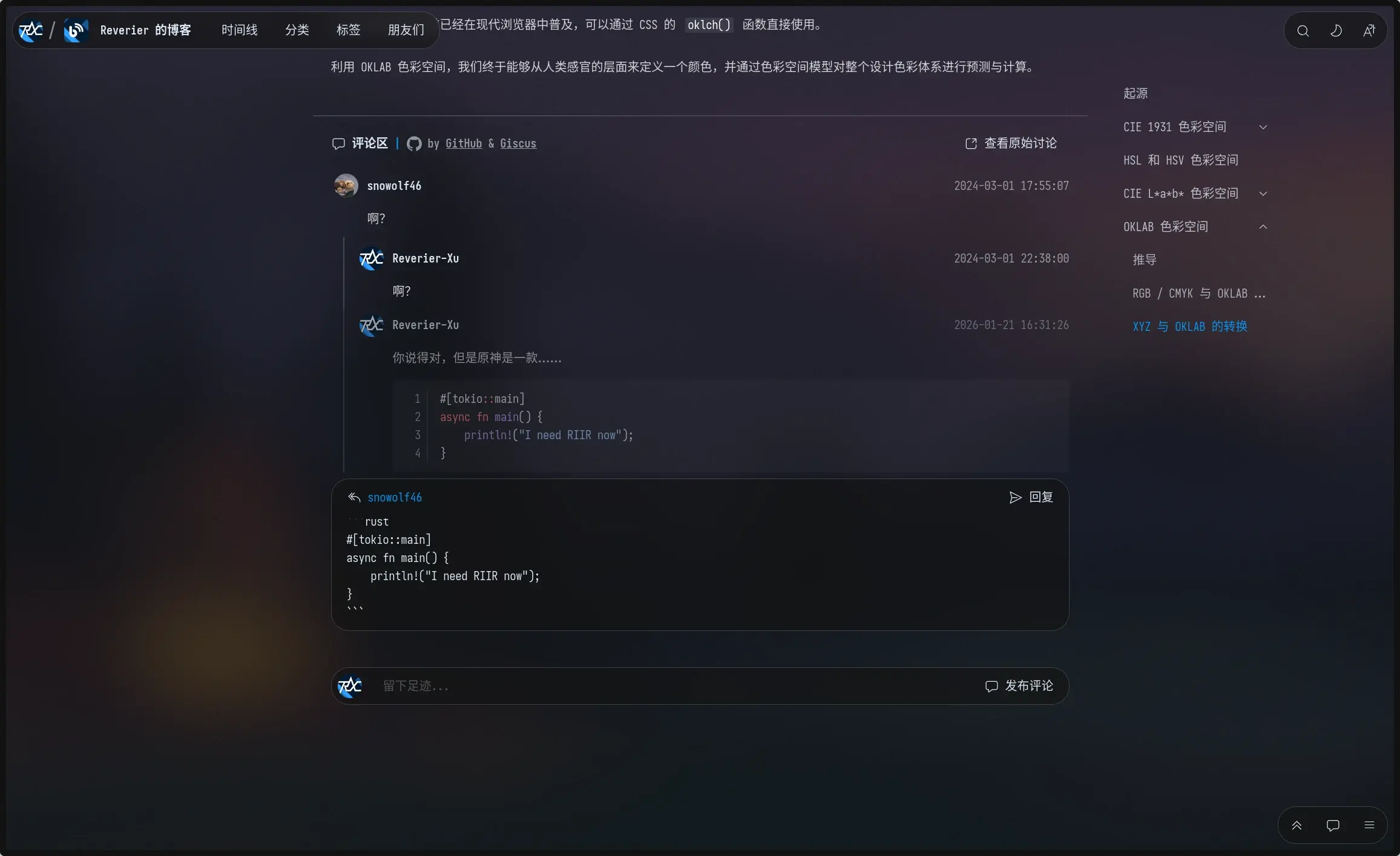
不过 GitHub API 返回的评论数据里并不是 Markdown,而是原始的 HTML 内容,所以这里可能并没有那么“所见即所得”。GitHub 的渲染工具没有本站功能那么丰富((
一些想法
关于 AI
2023 年就有一种论调,说 AI 最终会完全取代传统程序员,其实不然,我感觉可能永远不会,程序员也是会进化的。
在 2023 年早些时候,我就在用 Copilot 的智能提示补全功能了,这两年能够很明显的感觉到技术进步,从最开始的幻觉乱飞,到现在能够联动 LSP 自动判断导入规则,削减幻觉输出。AI token 的价格也在多家竞争之下一直降低,不过前几年还是为了能省点钱辗转于多家供应商之间,前后大概尝试了 GitHub Copilot,Fitten Code,ChatGLM,Gemini 和 Trae 等等,在内联代码补全这个赛道上大家已经做的差不多了,除了小厂的效果还差了点之外,内联补全已经进化到了非常顺手的程度。
在 2025 年,AI 工具开始向着多模态和 Agent 方向完善了。这两个概念很早就有研究和实现推进,但是直到 2025 年下半年大概才算成熟能用。第一次接触 Agent 也是 GitHub Copilot,在 VSCode 侧栏中更新的编码代理模式。这些天也看到网上已经给 AI 编程吹飞了,有很多没怎么接触过编程的人将 AI 奉为神明,然后薅着一个简单的提示词让 AI 接手全部工作等等等,更有一些人把自己不会写代码但是用 AI 糊出来一坨能跑的东西当成一件自豪的事…… 一时间不知道这到底是人类的进步还是退步。
不可否认的是,这些 AI 工具的确极高的提升了开发效率,工具是没有原罪的。但(不管是哪里来的)其舆论带来的负面影响也很大,在舆论加持下,越来越多的人在自己没有代码审计能力的情况下纷纷涌入开发的渠道,美其名曰:“降低开发门槛,让每个人都感受到开发的乐趣”,但实际上写出来的东西自己审不动,AI 审不动,甚至叫个资深程序员来都审不动,跑起来也只有某个流程能用,测试稍微发难一下就问题百出。在开源合作这边尤是如此,这半年一来在各个项目中已经见识到了不下数十个打着开源贡献旗号往代码库里推 AI 代码的同学了,用 AI 写代码本身并没有什么问题,但是写了之后不测试不审,甚至连编译运行都不愿意跑一下就往代码库里提 pr,实在是有点逆天。跟他们提出这个问题,他们还会以“守旧”、“不愿意接受新技术”、“不愿意承认自己会被替代/已经落伍”等等罪名往我身上扣。
我几个月前一边烦心秋招一边忙着毕设,还要应付这种内耗代码的时候,一度想在 README.md 里直接明文写出来不接受 AI 贡献,但工具确实是无罪的,有问题的只是人而已。
说回 AI 编程的话题,AI 的代码质量与编码能力确实是一直在提升的,但是它的本质并没有发生什么改变,依旧是基于预训练时使用的训练集,拼拼凑凑出一套能用的东西。在这种条件下,如何引导 AI 去正确地做事非常重要。首先,我们自己得有一套行之有效并易于维护的代码风格;在这个前提下,一步一步的将代码任务拆分成目标明确、路径明确并且资料比较丰富的数个小任务,然后再让 AI 去做,效果就会非常好。
如果类比一下的话,AI 就像是一个刚刚毕业、知识储备量惊人但是动手实践和应用能力基本为零的实习生,它并不适应某个完整项目的阶段性开发任务。最初 Agent 编程刚推出的时候,它基本上是将现有的代码片段拼拼凑凑输出一下,很容易在已有项目的后续开发里引入一些乱七八糟的依赖,引入多个运行时和库(甚至是过时的库,因为这些库的文字资料比更新的库要多得多),跑是能跑的,但是根本没法后续维护,我们根本审不动它写的乱七八糟的代码,它自己也审不动,审的时候还会丢上下文;截至目前,Agent 通过 MCP 等等协议,学会了自己去读项目代码,但它本质上依旧没有对整个项目结构与代码风格的认知。如果要实现一个全新的功能,它原先乱拼凑的问题依旧存在;如果是实现一些体力活,它其实是在借鉴其他模块的写法,如果上下文不巧引入了一些噪音,输出结果也不尽如人意。
最后,AI 取代的是工作,而不是人。在 影视飓风 的首页就有四个大字“无限进步”,感觉可以很好的描述我们如何应对 AI 所带来的浪潮。被浪潮拍在沙滩上的时候,应当好好反思一下,自己究竟是故步自封,还是没能看清泡沫本质。
关于以后
理想主义意味着可能永远得不到回报,尽管如此,仍然决定付出。
2025 依旧没有忘记这句话,希望 2026 也是。