

记录一些狗血历程,供大家嘲笑。
技术选型
在开发新平台之前,我仔细思考了一下我们的需求:
能够一次部署多次办比赛,同时常驻练习平台,降低运维压力。
考虑到协会每年要举办的比赛至少有四场:MoeCTF、Mini LCTF、D3CTF/LCTF、中学生比赛,每次比赛结束之后都要辛苦运维把所有题目都搬迁到 archive 平台上。对于 MoeCTF 和 Mini LCTF 来说,可能还需要在 archive 平台上直接举办比赛,之前一直使用的 CTFd 就出现了一些问题:
- 只能够举办单次比赛;
- 部署升级稍麻烦;
- 性能存在很大问题;
- 迁移合并比赛数据简直是灾难;
为了让以后办比赛不再这么折腾,还是换一个平台比较好。
前言
从前年我运维 moeCTF 2020 开始,我就一直试图寻找一个能解决 CTFd 痛点的新平台。具体了解过的平台与插件有:
- 赵总的 buuoj.cn, 多场比赛的解决方案似乎不开源,也不是很想继续在 CTFd 上做 monkey edit;
- HackTheBox, 不开源,不过模式可以参考;
- Mellivora, PHP 写的,看了看功能感觉也不太符合需求。
然后从 20 年磨蹭到 22 年上半年,期间经历了各种各样的麻烦事,也没有抽出来整块整块的时间写较大的工程项目,于是就一直搁置了。
然后就到了 22 年的暑假前,大概五月的时候。
miniL 前一个月 👴: 今年 miniL 必上新平台
miniL 赛前两天 👴: 写不完了,寄,CTFd 救救
miniL 结束之后 👴: 今年 MoeCTF 必上新平台
然后就开始这场苦逼旅途了。
语言?框架?
先后考察了
- Java: 语言和生态都很成熟,但是读了读一些据说质量很高的开源项目,一个函数能套出来
xxxWrapperHandlerControllerImpl这种名字……; - Python: 到我开写的时候,Python 3.9 还带着 GIL, 单核战士;
- C#: 之前写过一点 Winform, 感觉这门语言的设计好 NB, 于是去看 ASP.NET 的文档,但是看了一遍也没明白一次请求是怎么走到 Endpoint 的,莫名其妙就跑起来了,继续往下读被微软的机翻文档和奇怪的兼容性改动劝退;
- C++: 还真考虑过用 Qt 的 SocketServer 写一个,但……何必呢.jpg, orm 啥的轮子还得自己造;
- NodeJS: 语言本身特性就挺劝退的;
- Go: (吃完晚 (早?) 饭看了几个小时入门教程) 好!大道至简!我现在是 Golang 带师!
于是最后入了 go 的坑,Web 请求框架用了 gin, 数据库用了 PostgreSQL + GORM.
在前端选型上纠结了一会儿 vue 和 react, 最终选择了 vue3, 感觉前端框架用起来都大差不差,vue3 的组织方式更符合我的直觉一些。
前端组件库用的这个:Naive UI.
SSR?CSR?
其实我是比较偏向服务端渲染的,这样用户点开页面就能看见信息,前端编写难度也会降低一些,不用为了一些异步请求搞占位符、skeleton 啥的。不过考察了一圈子 vue 的库发现情况并没有我想的那么好,大部分方案都是针对 NodeJS 作为后端的,而且并没有一个能跟 go 后端配合很好还特性稳定的方案。基本上搜起来 go+vue 都是前后端分离式项目。
后来决定使用客户端渲染,因为前后端都在同一台服务器上,倒也不太担心会对用户体验造成什么太大的影响。
最后决定下来就拿 Go 和 Vue 3 写一个前后端分离式的平台了。
数据库设计
技术栈确认下来之后,接下来简单搭建了一下脚手架,下一步就是进行数据库设计。
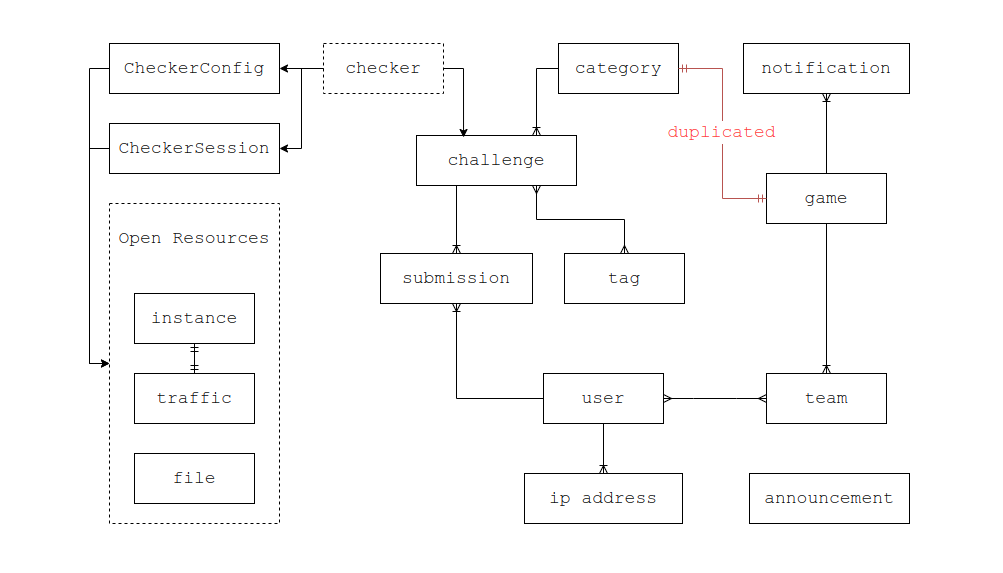
Cyber Terminal 与 CTFd 最大的区别就是拥有举办甚至同时举办多场比赛的能力,同时能够自动进行题目归档等工作。所以数据库设计上除了参考 CTFd 的现有设计之外,还要多出一些考虑。
具体的数据库设计如下:
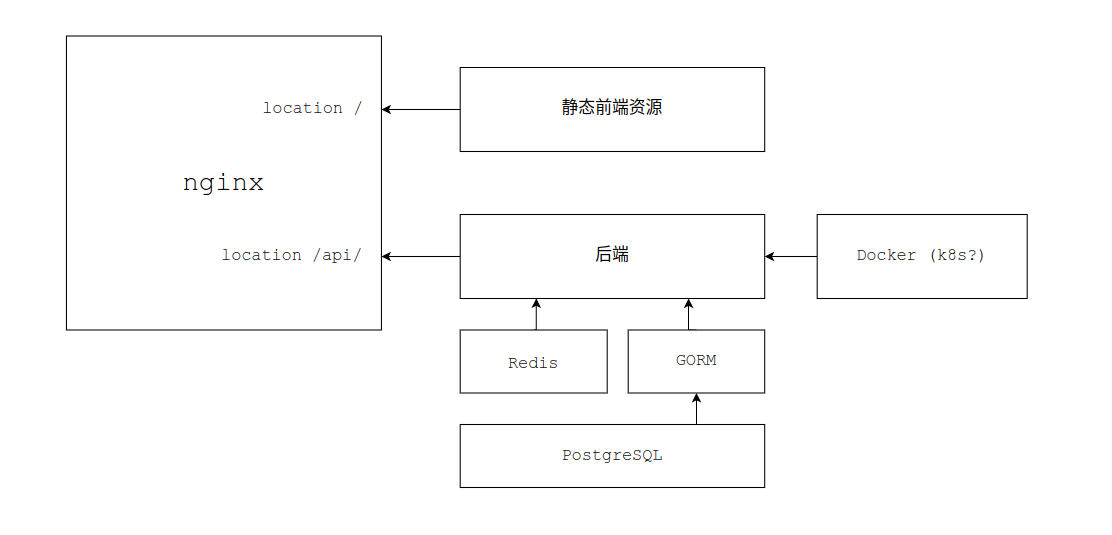
整体网站架构的设计如下:
其中将 game 和 category 分开属于设计失误,打算在下一个版本更新中迁移合并。
当时设计的时候我想着,如果要给平台添加练习场的话,应当有一个“分类”的概念,而比赛归档时刚好就可以作为同一个“分类”而归档。而对于题目本身的性质而言,一道题目只能归类于一个“分类”有些生硬,于是我将类似于“web”、“pwn”这一类概念从“category”改为了“tag”, 这样一道题目就可以有多个标签,也起到了分类的作用。而原有的分类,就作为组织题目来源的一种方式来使用。但是后来在实现上发现 category 与 game 本身就是一对一的关系,但是由于拆分开了,为数据库操作增添了许多不便,属于完全多余的设计,还为此写了很多屎山代码。
CTF 的题目类型比较多样,有静态附件题目,动态容器题目,还有之前为了反作弊实现的动态附件题目,甚至还包括一些需要评测的 ACM 题,总体来说需求各不相同。于是我设计了“checker”来表示不同的题目类型,题目可以通过多态关联到某个特定类型的 checker 上,然后与 checker 相关的数据就直接存在对应 checker 实现中。而 checker 在具体使用中也要有针对 challenge 的数据存储与针对 user 的数据存储,我在这里设计了 checkerConfig 和 checkerSession . 前者用来与 challenge 一对一关联,存储该类型题目的相关设定,例如静态 flag、动态 flag 模板、静态附件、容器题目的 docker 镜像与配置等等等,而 session 则是与 challenge+user 进行唯一关联,当 user 尝试访问 challenge 的时候就会自动建立此模型,里面可以存放一次性生成的动态 flag、已启动容器的状态与访问方式等等等。
checker 的组织方式与 CTFd 稍有不同,CTFd 将 题目、flag 类型 等都通过暴露内部 API 的方式提供给插件实现,我觉得似乎没有什么必要,索性就组合成为一个 checker. 同时 CTFd 是不具备 session 管理能力的,需要在插件中自行管理数据库,既然这样不如直接把这个概念一起做进去。
开发日记 01
👴 脑子真的是抽抽了才会用 GORM
时间回到六月,👴 好不容易忙完手头的 p 事,打算开干。先是花半天时间确定了技术栈、框架之类的东西,然后设计了一下数据库结构,就开始上手写后端。
在写的时候为了图方便,就找了一个看似很好用很 nb 的 GORM. 结果写四行代码能踩俩坑。
为什么是四行代码?有三行是
if err != nil { return nil, err }
首先,GORM 的 API 并不是统一的:
// 返回值是 *Cmd, 可以继续往后链式调用,虽然不知道都写到 First 了后面还能有什么
// 如果想获取到这一行的错误时,要使用 *Cmd.Error, 返回类型为 errors.Error
err := db.Model(&models.User{}).Where("name = ? and verified = ?", name, true).First(&user).Error
// 但是在 Association API 中,返回值直接就是 errors.Error, 这个时候如果再往后面接一个 Error(), 结果就是 err 字符串
err := db.Model(&models.Team{}).Where("id = ?", teamID).Association("Users").Find(&users)其次,他自己文档里的实例跑不动:
// 里面有这么一段用来自定义 JSON 字段的东西
type JSON json.RawMessage
// Scan scan value into Jsonb, implements sql.Scanner interface
func (j *JSON) Scan(value interface{}) error {
// 这里就有问题,实际上 value 是个 str, 于是转换失败直接寄了
bytes, ok := value.([]byte)
if !ok {
return errors.New(fmt.Sprint("Failed to unmarshal JSONB value:", value))
}
result := json.RawMessage{}
err := json.Unmarshal(bytes, &result)
*j = JSON(result)
return err
}
func (j JSON) Value() (driver.Value, error) {
if len(j) == 0 {
return nil, nil
}
// 但是很奇怪的是这里吐出去的是个 [] byte, 👴 怀疑是他从数据库里取数据的时候没有保证前后一致
return json.RawMessage(j).MarshalJSON()
}再然后,那个 关联模式 (Association Mode) 就是个半成品。
根据 👴 不多的数据库原理分数,👴 想起来数据库的关系模型分为三种:一对一,一对多,多对多。结果打开文档一看有四种:belongs to, has one, has many, many to many, 吓得我又去搜了一下 what is the difference between has one and belongs to?出来的链接除了第一个是 ThinkPHP5, 剩下全是 GORM.
👴: 草,我数据库原理白学了
(搜)
👴: …
👴: 什么自创关系模型
然后 👴 想着应该大差不差,凭感觉写一写,在之前的设计中,submission 和 user 与 challenge 都是一对多关系,在使用场景下也需要根据 submission 查 user 或者根据 user 查 submission.
👴: 那 submission belongs to challenge, challenge has many submissions
👴: 没毛病
(写、跑、寄了,草)
👴: ?
仔细读了一遍文档,发现 belongs to 和 has one 都属于一对一关系,看来是 👴 读文档不仔细,挨一锤。
于是 👴 仔细看了看两个一对一关系有啥区别:
// 文档里这个叫 belongs to
type Game struct {
ID uint
...
Category *Category // <-
CategoryID uint
}
type Category {
ID uint
...
}
// 这个叫 has one
type Game struct {
ID uint
...
CategoryID uint
}
type Category {
ID uint
...
Game *Game // <-
}建出来的数据表都是 games 中有一个 category_id 列,和完全相同的关联约束,区别只是一个 Game 结构体里包含 Category, 一个 Category 结构体里包含 Game.
👴: 这有啥区别?奇怪的 feature🐎
👴: 那 👴 只写一个键,在两边都内置一个对面的结构体指针应该没事吧,这里面要加载另一个表需要显式 preload 的,倒也不会循环引用
(写、跑、寄了,草)
👴: ** ** ** ** ****
于是出现了一个尴尬的情况,无论用哪种方式,都只能在一个数据模型上使用 Association Mode, 另一个模型只能手动过滤列:
// 用 Association 通过 game 查 category, 彳亍
db.Model(&models.Game{}).Where("id = ?", gameID).Association(&models.Category{}).First(&category)
// 用 Association 通过 category 查 game, 真不彳亍
db.Model(&models.Category{}).Joins("inner join games on games.category_id = categories.id and categories.id = ?", categoryID).First(&game)
// 那 👴 干嘛不这样写
db.Model(&models.Game{}).Where("category_id = ?", categoryID).First(&category)
// 👴: 这 Association Mode 存在的意义是啥同理,has many 也有这样的问题。
在后面开发的时候 👴 基本上是开着 Debug 模式一路写过去的,每次写完都要跑一次让 GORM 输出一下他构造好的 SQL 长什么样,符不符合 👴 的预期,然后发现了一大堆各种各样的奇怪问题,这里就不详述了。
👴: 啥啥啥,这写的是个啥,怎么 User 里 创建的时候有个 Languages 一会儿 过滤的时候又变成了 codes, 你们写文档都不带 🧠 放一下原始结构体到底长啥样 🐎